
ü 引用本文
________________________________________________________________________________________________________________________
引用格式:杨建秀,胡正平.稀疏FRAME模型的感兴趣目标检测算法[J].四川兵工学报,2014(12):107-111.
Citation format:YANG Jian-xiu,HU Zheng-ping. Object Detection Algorithm Based on Sparse ERAME Model[J]. Journal of SichuanOrdnance, 2014(12):107-111.
________________________________________________________________________________________________________________________
基金项目: 国家自然科学基金(61071199);河北省自然科学基金(F2008000891, F201000129);中国博士后自然科学基金(20080440124);第二批中国博士后基金特别资助(200902356)。
________________________________________________________________________________________________________________________
作者简介:杨建秀(1985-),女,硕士,主要从事图像处理、统计学习模式研究。
稀疏FRAME模型的感兴趣目标检测算法
杨建秀1,胡正平2
(1.山西大同大学物理与电子科学学院,山西大同 037009;
2.燕山大学信息科学与工程学院,河北秦皇岛 066004)
摘要:针对基于非齐次FRAME(Filters,Random filed,And Maximum Entropy)模型的目标检测算法在目标发生较大形变或存在阻挡等情况下的定位产生一定偏差,以及学习模型所需大量时间等各方面的研究,提出了一种稀疏FRAME模型的感兴趣目标检测算法。首先用共享稀疏编码方法对样本图像进行特征提取,由所选择的基函数构成可变形的稀疏FRAME模型;然后用交替的求和图及最大值图结构对测试图像进行匹配检测,实现目标定位。经多组实验结果表明,该算法不仅在一定程度上提高目标发生较大形变或存在阻挡等情况下的鲁棒性,而且节省了大量的样本训练时间。
关键词:目标检测;稀疏模型;共享编码;非齐次
中图分类号:TP391.41 文献标识码:A 文章编号:1006-0707(2014)12-0107-05
Object Detection Algorithm Based on Sparse FRAME Model
YANG Jianxiu1, HU Zhengping2
(1.School of Physics and Electronics Science,ShanxiDatongUniversity,
Datong Shanxi 037009; 2.School of Information Science and Engineering,
Yanshan University,QinhuangdaoHebei066004)
Abstract: Object detection algorithm based on inhomogeneous FRAME model was difficult to solve the problem when target occurred large deformation or the presence of occlusion, and needed a lot of time on training model, so this paper presented a detection algorithm of object-of-interest based on sparse FRAME model to solve these problems. Firstly, the algorithm selected features via a shared sparse coding scheme, and formed the deformable sparse FRAME model by selecting shared basis functions. Secondly, the matching of the sparse FRAME template to a testing image could be accomplished by a cortex-like structure of recursive sum-max maps. The experimental results show that this method is robust when target occurred large deformation or the presence of occlusion, and saves a lot of training time.
Keywords: detection; sparse model; shared coding; inhomogeneous; deformable
近年来,目标检测技术受到极大关注,但由于如目标存在遮挡、形变、视角或光照变化造成目标姿态的复杂性等问题,导致解决这些问题下的目标定位存在着许多困难。针对感兴趣目标检测与定位算法,文献[1-2]中提出弱假设:感兴趣物体通常大致在图像的中央位置,该弱假设忽略了感兴趣物体的主观性,所以适用范围不大。在感兴趣目标存在模板的情况下,文献[3]中采用自底向上的聚合方法锁定感兴趣目标,该方法由于缺乏上层信息导致目标模式不清晰,对存在遮挡的感兴趣目标检测存在一定的困难。而自顶向下的检测算法中,文献[4]中利用上层形状信息定义目标模式,通过多次旋转区域轮廓来匹配目标形状实现目标定位,但是每次采样都需要重复匹配,计算量太大。非齐次模型[5](Inhomogeneous Filters,Random filed,And Maximum Entropy,简写为IFRAME)结合自底向上和自顶向下的方法进行推理,既得到图像在各个方向和尺度上的特征,又可得到其先验知识,但学习IFRAME模型要重构样本所有位置、方向和尺度上的响应,因此该模型是一种密集型的目标模式,训练样本时对计算和推理要求苛刻,需要大量的参数;同时该模型并不能很好地表示感兴趣目标的各种形变,对较大形变的感兴趣目标定位存在一定的困难,为此本文对IFRAME模型进行稀疏化得到稀疏FRAME模型。稀疏FRAME模型利用稀疏编码方案选择特征,和基于稀疏编码的现有方法[6-8]相比,该模型明确定义了一个关于图像强度的概率分布,且能从概率分布的抽样中合成新图像,并重构训练样本,因此该模型既可以明确目标的模式,消除了由弱假设定义感兴趣目标所带来的客观性,提高感兴趣目标定位的准确度,又提高了训练样本的速度;同时学习到的先验信息可以扰动对应模型的位置和方向去匹配形状变形的目标。实验结果表明稀疏FRAME模型的检测算法提高了复杂环境下目标定位的准确率。
1系统组成框图
框图1给出基于稀疏FRAME模型的感兴趣目标检测定位系统。该算法包括2个关键的部分:在线性叠加框架下用共享稀疏编码选择基函数,从而利用非监督的方式来训练稀疏FRAME模型;然后在测试图像上通过交替求和图及最大值图(sum-max maps)的计算框架计算出与稀疏FRAME模型匹配分数最高的区域,从而实现目标定位。
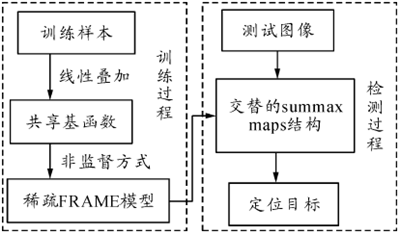
图1 基于稀疏FRAME模型的目标监测系统框图
2传统的FRAME模型
FRAME模型是一种空间平稳的马尔科夫随机场模型,且服从最大熵分布,该模型利用多滤波器的选取,实现目标边缘直方图响应的重构,边缘直方图能共享图像区域中所有像素,从而可得到图像或纹理在各个尺度和方向上的特征,对更加复杂的纹理样式进行建模。实验表明,该模型能有效地分割含有复杂纹理的图像。
2.1Inhomogeneous FRAME模型
在FRAME模型的基础上,朱松纯等[9]又提出一种空间不平稳随机场模型IFRAME,该模型同样服从最大熵分布,重构滤波器中每个位置、方向和尺度上的响应分布或统计,但不存在空间上的共享。实验表明该模型能产生多样的感兴趣目标模式来代替纹理模式,实现感兴趣目标的检测与定位。
IFRAME模型是利用大致对齐的同一类物体进行建模,设定{Im,m=1,…,M}是一组训练样本,定义在图像域D上,Bx,s,α为构成样本图像的基函数,〈I,Bx,s,α〉是图像I在像素x、尺度s、方向α的滤波响应,其基函数标准化。IFRAME模型是定义在图像I的概率分布
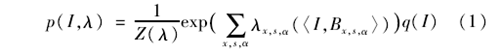
其中:q(I)是一个已知的参照分布,比如它可以是一个高斯白噪声(最简单的背景分布模型);λx,s,α是滤波器响应的绝对值系数;Z(λ)为归一化常数。在随机纹理模式FRAME模型中,λx,s,α( [I,Bx,s,α])和x没有关系,只取决于s和α,所以FRAME模型在空间上是稳定的。而作为目标模式的IFRAME模型,λx,s,α(〈I,Bx,s,α〉)除了取决于s和α,还必须取决于x,导致IFRAME在空间不稳定,同时要利用每一个x去估算λx,s,α(〈I,Bx,s,α〉),对于数量较小的训练样本集,将其参数化λx,s,α(r)=λx,s,α|r|,其中r=〈I,Bx,s,α〉为滤波器响应。
2.2模型学习
IFRAME模型中参数λ={λx,s,α,∨x,s,α}是利用训练图像Im,{ m=1,…,M}通过最大似然估计[8](Maximum likelihood learning,MLE)进行估算的,同时将λ(t)作为当前模型参数λ的估计,{I(~)m,m=1,2,…,M(~)}作为p(I;λ(t))合成图像的一个样本,利用式(2)不断更新λ
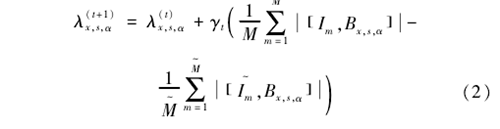
其中γt是步长,合成图像{I(~)m}利用p(I;λ)勾画[10]得到。归一化常数的比率为
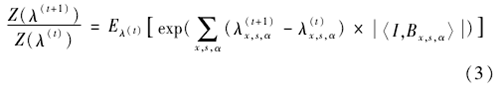
起始值λ(0)=0,Z(λ(0))=0,在学习过程中计算logZ(λ(t))从而可得到IFRAME模型。图2所示是3种类别训练样本学习IFRAME模型的合成图像。



图2 IFRAME模型的合成图像
3稀疏FRAME模型的定位过程
上述实验表明,学习IFRAME模型要重构样本图像所有位置、方向和尺度上的响应,因此该模型是一种密集型的目标模式,训练样本时对计算和推理要求苛刻,需要大量的参数,计算量非常大;同时训练得到的模型并不能很好地表示感兴趣目标的各种形变,对较大形变的感兴趣目标定位会发生一定的偏差,为此本文对IFRAME模型进行稀疏化得到稀疏FRAME模型。
感兴趣目标定位过程主要包括2个步骤:①通过共享稀疏编码模型学习得到稀疏FRAME模型;②采用自底向上和自顶向下结合的检测算法定位感兴趣目标。
3.1稀疏FRAME模型
在模型(1)中,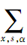 中(x,s,α)是指所有的像素x、尺度s、方向α,文中通过选择(x,s,α)的一部分来稀疏该模型,同时把
中(x,s,α)是指所有的像素x、尺度s、方向α,文中通过选择(x,s,α)的一部分来稀疏该模型,同时把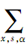 限制在选择的子集中,可更明确地把稀疏模型写成如下形式:
限制在选择的子集中,可更明确地把稀疏模型写成如下形式:
可变形的共享稀疏编码模型为
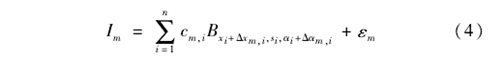
稀疏FRAME模型为
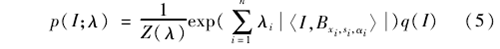
其中:λ=(λi,i=1,…,n)为系数;n为所选择基函数的个数;(Bxi,si,αi,i=1,…,n)是训练图像共享基函数所选择的子集。(Δxm,i,Δαm,i)是第m幅图像中第i个基函数位置和方向的扰动范围,因此这些共享的基函数可以扰动自己的位置和方向去匹配形状变形,从而使稀疏FRAME模型能够自适应地对较大形变目标进行匹配,实现感兴趣目标定位;同时学习模型的计算量也大大降低,提高了训练样本的速度。
稀疏FRAME模型学习算法由2部分组成:①利用共享稀疏编码选择B=(Bxi,si,αi,i=1,…,n);②通过选择的B估算λ=(λi,i=1,…,n)。
本文利用最小化训练图像中重构误差的总和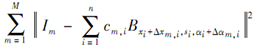 的思路来选择{Bxi,si,αi,i=1,…,n},具体算法是对匹配追踪算法[11]进行扩展,实现基函数的选择,达到多图像同时编码的目的,同时通过局部最大共享[12]实现基函数的局部扰动。具体算法如下:
的思路来选择{Bxi,si,αi,i=1,…,n},具体算法是对匹配追踪算法[11]进行扩展,实现基函数的选择,达到多图像同时编码的目的,同时通过局部最大共享[12]实现基函数的局部扰动。具体算法如下:
1)初始化:i=0,残差图像εm=Im,m=1,…,M。
2)令i=i+1。
3)选择基元:在所有(x,s,α)寻找最大的(xi,si,αi),(xi,si,αi)=arg max x,s,α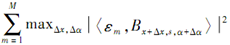 其中maxΔx,Δα是在Δxm,i和Δαm,i的范围内所共享的局部最大值。
其中maxΔx,Δα是在Δxm,i和Δαm,i的范围内所共享的局部最大值。
4)对于每一个m中给定的(xi,si,αi),通过检索[3]中共享的局部最大值arg max可以推断出扰动的位置和方向:
(Δxm,i,Δαm,i)=arg maxΔx,Δα|〈εm,Bxi+Δx,si,αi+Δα〉2|
5)令系数Cm,i=〈εm,Bxi+Δxm,i,si,αi+Δαm,i〉。
6)更新残差图像:εm=εm-Cm,Bxi+Δxm,i,si,αi+Δαm,i。
7)如果i=n则停止算法,否则返回2)。
在选择B={Bi=Bxi,si,αi,i=1,…,n }后,利用式(5)对训练图像{Im}进行建模,同样通过MLE来估计λ。在迭代学习算法中,令λ(t)为当前λ的估计值,令{I(~)m,m=1,…,M(~) }是从p(I;λ(t))利用M(~)平行链绘制出的合成图像,然后利用式(6)更新λ得到稀疏FRAME模型。
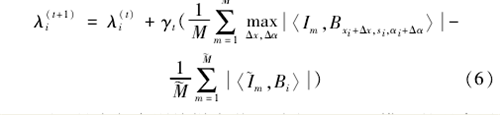
图3是自行车训练样本学习稀疏FRAME模型的混合图像。图3(a)图为训练图像,图3(b)图为对应的可变形模板(Bxi+Δxm,i,si,αi+Δαm,i,i=1,…,n)的勾画草图,图3(C)为对应的重构图像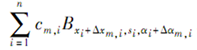 ,图3(d)图为残差图像εm。图4是自行车的稀疏FRAME模型。图5是3种类别训练样本学习稀疏FRAME模型的合成图像。
,图3(d)图为残差图像εm。图4是自行车的稀疏FRAME模型。图5是3种类别训练样本学习稀疏FRAME模型的合成图像。

图3 自行车训练样本学习的稀疏FRAME模型的混合图像

图4 自行车的稀疏FRAME模型

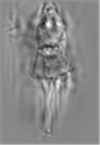

图5 稀疏FRAME模型的合成图像
3.2感兴趣目标定位
基于稀疏FRAME模型的感兴趣目标定位算法是利用交替的sum-max maps计算框架[13-14]结合自底向上和自顶向下算法[15]实现的。其主要包括2个过程:自底向上检测和自顶向下定位。自底向上检测是在sum-max maps结构上利用稀疏FRAME模型对测试图像进行扫描匹配,从而确定测试图像中感兴趣目标的位置;而自顶向下算法是找到与测试图像感兴趣物体最匹配的轮廓,从而实现目标的精确定位。Max maps的计算将可变形的稀疏FRAME模型匹配图像数据,Sum maps的计算则使用变形后模型的对数似然对模板匹配进行打分。
通过学习到的稀疏模型作为一个可变形模板去匹配测试图像的每个位置,其每个位置的模板匹配分数都可用式(7)对数似然比计算得到,对所有匹配分数取全局最大值,得到与稀疏FRAME模型最适配的感兴趣目标的位置,从而实现感兴趣目标的定位
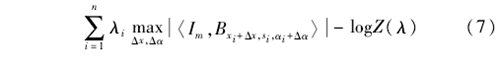
4实验结果与分析
为了验证算法的性能,本文进行3种常见类别感兴趣目标检测定位实验。其中图6、7、8分别给出汽车、人、自行车3种类别的定位实验结果,图9为自行车发生较大形变时检测的对比实验结果。


(a)未发生形变时定位实验结果


(b)在不同主方向时定位实验结果


(c)存在遮档时定位实验结果


(d)复杂环境下定位实验结果
图6 汽车定位结果
图6分别表示为目标汽车和对应的稀疏FRAME模型观测角度大致相同、和对应学习模型具有不同主方向(相对训练样本发生形变)、存在遮挡影响以及存在于复杂环境4种情况的实验定位结果,其中左列图为检测图像,右列图为检测结果。
图7分别表示为感兴趣物体自行车和对应稀疏FRAME模型的观测角度大致相同、相对学习模型发生形变、存在遮挡以及存在于复杂环境下的4种情况的实验定位结果,其中左列图为检测图像,右列图为检测结果。
图8分别表示为感兴趣目标人和对应的稀疏FRAME模型观测角度大致相同、相对训练样本发生形变、存在遮挡以及存在于复杂环境下4种情况的实验定位结果,其中左列图为检测图像,右列图为检测结果。从图6、7、8中可以看出,本文算法对目标发生形变、存在遮挡等复杂环境下都能进行正确的定位。


(a)未发生形变时定位的试验结果


(b)发生形变时定位的实验结果


(c)存在遮档时定位实验结果


(d)复杂环境下定位实验结果
图7 自行车定位的结果


(a)未发生形变时定位实验结果


(b)在不同主方向时定位实验结果


(c)存在遮挡时定位实验结果


(d)复杂环境下定位实验结果
图8 人定位结果
图9给出了用本文方法和基于IFRAME模型的检测算法在INRIA Person数据集中检测自行车的部分实验结果,从图9中可以看出,基于IFRAME模型在自行车发生较大形变时的定位目标容易出错。


(a)本文方法的检测结果


(b)IFRAME模型的检测结果
图9 自行车发生形变检测对比实验结果
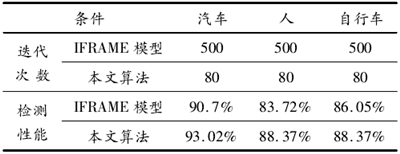
本文实验是在Windows7系统Matlab R2010a,Visual2008C++ Compiler环境下实现的。尽管测试图像来源不同,感兴趣目标的特性存在差异,但是本文所提的检测方法具有良好的检测性能。表1给出了2种模型的检测性能对比实验结果,及训练模型所需的迭代次数,实验图像为课题组建立的43幅单一目标的图像,从实验结果可以看出本文方法在提高训练模型效率的同时,还具有相对较好的检测性能。
表1 实验统计性能分析
5结束语
对于传统的IFRAME模型训练样本时需要大量的参数,计算量大而且推理要求苛刻,同时训练的模型对解决目标发生较大形变、存在遮挡等受干扰下定位存在的困难,提出了稀疏FRAME模型检测算法。该模型由稀疏编码模型选择合适的基函数组成,而这些基函数可以在一定的范围内进行扰动,因此能实现模板的精确匹配,同时降低训练样本的计算量;由于稀疏FRAME模型具有稳定性,不受光照、视角、类间变化的影响,适用于复杂环境下的感兴趣目标检测。实验结果表明,本文算法能同时提高定位的准确率和效率,具有较强的实际应用价值,为中高级计算机视觉问题提供了良好预处理手段。
________________________________________________________________________________________________________________________
参考文献:
[1]KIM S,PARK S,KIM M. Central object extraction for object-based image retrieval[M]. Heidelberg:Springer Berlin,2003:523-528.
[2]HUA G,LIU Z,ZHANG Z. Iterative local-global energy minimization for automatic extract object of interest[J]. IEEE Transaction on Pattern Analysis and Machine Intelligence,2006,28(10):1701-1706.
[3]KO BC,NAM JY. Object-of-interest image segmentation based on human attention and semantic region clustering[J]. Journal of the Optical Society of America,2006,23(10):2462-2470.
[4]WANG J,GU E. Mosaic shape:stochastic region grouping with shape prior[C]//Proceedings of the Computer Vision and Pattern Recognition. San Diego,CA,United states:IEEE,2005, 1:902-908.
[5]XIE JW,HU WZ,ZHU SC,et al. Learning inhomogeneous FRAME models for object patterns[EB/OL].[2014-05-06]. http://www.stat.ucla.edu/~jxie/iFRAME.html.
[6]JHOU I,LIU D,LEE D.T,et al. Robust visual domain adaptation with low-rank reconstruction[C] // Proceeding of the Computer Vision and Pattern Recognition. Providence, RI USA:IEEE, 2012:2168-2175.
[7]OBOZINSKI G,WAINWRIGHT M.J,JORDAN M. I. Support union recovery in high-dimensional multivariate regression[J]. Annals of Statistics,2011,39(1):1-47.
[8]ZEILER M,TAYLOR G,FERGUS R. Adaptive Deconvolutional networks for mid and high level feature learning[C]// Proceeding of the International Conference on Computer Vision. Barcelona,Spain:IEEE,2011:6-13.
[9]LIU C,ZHU SC,SHUM H.Y. Learning inhomogeneous Gibbs model of faces by minimax entropy[C]//Proceeding of the International Conference on Computer Vision. Vancouver,BC: IEEE,2001,1:281-287.
[10]BROOKS S,GELMAN A,JONES G L. Handbook of Markov Chain Monte Carlo[M]. New York:Chapman & Hall/CRC,2012:113-162.
[11]MALLAT S,ZHANG Z. Matching pursuit in a time-frequency dictionary[J].IEEE Transactions on Signal Processing,1993,41(5):3397-3415.
[12]RIESENHUBER M,POGGIO T. Hierarchical models of object recognition in cortex[J]. Nature Neuroscience,1999,2(5):1019-1025.
[13]SERRE T,WOLF L,BILESCHI S. Robust object recognition with cortex-like mechanisms[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(3): 411-426.
[14]MUTCH J,LOWE D G. Object class recognition and localization using sparse features with limited receptive fields[J]. International Journal of Computer Vision,2008,80(1):45-57.
[15]WU YN,SI ZZ,GUO HF,et al. Learning active basis model for object detection and recognition[J]. International Journal of Computer Vision,2010,90(2):198-235.
